SQLBolt 课程学习笔记三 (9-12 课)
文章目录
继续上课。
SQL Lesson 9: Queries with expressions
第 9 课,表达式查询。
In addition to querying and referencing raw column data with SQL, you can also use expressions to write more complex logic on column values in a query. These expressions can use mathematical and string functions along with basic arithmetic to transform values when the query is executed, as shown in this physics example.
我们不仅仅可以在原始数据上查询和应用,还可以通过写查询表达式来构建复杂一些的逻辑对列执行判断。表达式可以使用数学和字符语句函数结合算术方法来转换查询结果。比如下面这个物理学的例子:
|
|
Each database has its own supported set of mathematical, string, and date functions that can be used in a query, which you can find in their own respective docs.
数据库一般都有自己支持的一套数学、字符和日期相关的函数功能用于查询,可以查看文档。
The use of expressions can save time and extra post-processing of the result data, but can also make the query harder to read, so we recommend that when expressions are used in the SELECT part of the query, that they are also given a descriptive alias using the AS keyword.
使用表达式可以节省时间,避免对结果的再处理,但同时也会使得查询语句可读性降低。因而推荐的做法是,当 SELECT 语句中使用表达式时,通过 AS 给查询起个别名。比如:
|
|
In addition to expressions, regular columns and even tables can also have aliases to make them easier to reference in the output and as a part of simplifying more complex queries.
另外,数据的列和表格都可以有别称,这样有助于引用,也可以简化复杂的查询语句。比如:
|
|
练习时间
You are going to have to use expressions to transform the BoxOffice data into something easier to understand for the tasks below.
使用表达式转换 BoxOffice 数据使得其更好理解。用到的表格还是前面那个:
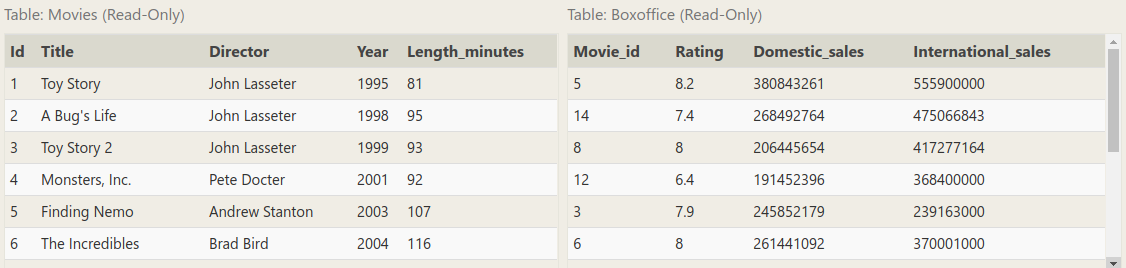
1. List all movies and their combined sales in millions of dollars
列出所有电影及其总票房(百万为单位),就是数学计算咯
|
|
(为了结果好看一点我按总共票房降序排列了。)
2. List all movies and their ratings in percent
列出所有电影及其百分比评分,感觉和第 1 题一样啊:
|
|
而且我开始写的 (Rating / 10) * 100 AS Rating_pct 不知道为什么就是不行。
- List all movies that were released on even number years
所有偶数年发行的电影,判断余数是否是 0 咯:
|
|
搞定收工。
SQL Lesson 10: Queries with aggregates (Pt. 1)
第 10 节课,聚合 (一)。预感从这里开始会有点小难。
In addition to the simple expressions that we introduced last lesson, SQL also supports the use of aggregate expressions (or functions) that allow you to summarize information about a group of rows of data. With the Pixar database that you’ve been using, aggregate functions can be used to answer questions like, “How many movies has Pixar produced?”, or “What is the highest grossing Pixar film each year?”.
除了上节课介绍的简单的表达式之外,SQL 也支持聚合表达式(或函数)从而可以使多行数据分组归纳。比如之前的皮克斯电影数据,通过聚合我们可以回答“皮克斯每年生产几部电影?”、“皮克斯每年票房最高的电影是什么?”之类的问题。语法:
|
|
Without a specified grouping, each aggregate function is going to run on the whole set of result rows and return a single value. And like normal expressions, giving your aggregate functions an alias ensures that the results will be easier to read and process.
没有特定的分组的时候,聚合功能会直接作用于所有行并返回单个值作为结果。跟上节课提到的一样,给聚合函数起个别名也会使结果更易读和更易于后续处理。
Common aggregate functions
常见的聚合函数
| Function | Description |
|---|---|
| COUNT(*), COUNT(column) | A common function used to counts the number of rows in the group if no column name is specified. Otherwise, count the number of rows in the group with non-NULL values in the specified column. |
| MIN(column) | Finds the smallest numerical value in the specified column for all rows in the group. |
| MAX(column) | Finds the largest numerical value in the specified column for all rows in the group. |
| AVG(column) | Finds the average numerical value in the specified column for all rows in the group. |
| SUM(column) | Finds the sum of all numerical values in the specified column for the rows in the group. |
Grouped aggregate functions
分组聚合
In addition to aggregating across all the rows, you can instead apply the aggregate functions to individual groups of data within that group (ie. box office sales for Comedies vs Action movies). This would then create as many results as there are unique groups defined as by the GROUP BY clause.
除了所有行聚合之外,我们还可以对分组的行每组进行聚合(比如对喜剧片和动作片分别统计票房)。这样可以得到由 GROUP BY 定义的组别一样多的结果。通俗点说就是,分组一共得到几组,聚合得到的结果就有几个。语法:
|
|
The GROUP BY clause works by grouping rows that have the same value in the column specified.
GROUP BY 的分组依据是分组所指定列具有相同值的行分到一组。
练习
For this exercise, we are going to work with our Employees table. Notice how the rows in this table have shared data, which will give us an opportunity to use aggregate functions to summarize some high-level metrics about the teams. Go ahead and give it a shot.
这次练习 又用到前面那个 Employees 表格:
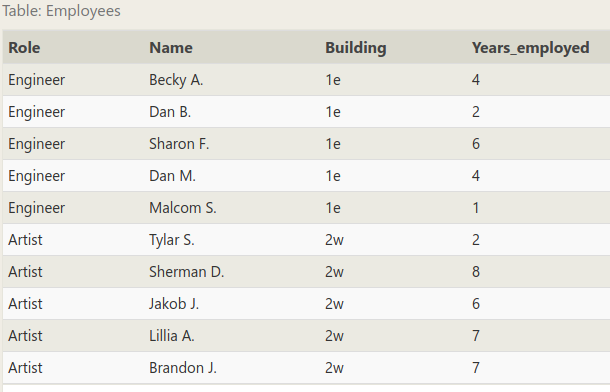
可以看到表格中有的行有重复数据(比如 Role 和 Building),这就提供了聚合归纳得到更高级别数据的机会。试试吧:
1. Find the longest time that an employee has been at the studio
找到雇佣时间最长的雇员。 嗯,雇员分组,时间求和,时间降序排列取第一个就是最长了:
|
|
2. For each role, find the average number of years employed by employees in that role
对于每种工种计算平均工作年限,那就是 Role 分组,时间平均咯:
|
|
3. Find the total number of employee years worked in each building
计算每栋楼里所有雇员的总工作时间。楼分组,时间加和咯:
|
|
竟然出奇的简单,开三。
SQL Lesson 11: Queries with aggregates (Pt. 2)
第 11 课,聚合(二)。
Our queries are getting fairly complex, but we have nearly introduced all the important parts of a SELECT query. One thing that you might have noticed is that if the GROUP BY clause is executed after the WHERE clause (which filters the rows which are to be grouped), then how exactly do we filter the grouped rows?
现在我们的查询语句已经有点小复杂了,但是其实 SELECT 语句的重要部分还没完全讲完。可以发现 GROUP BY 是在 WHERE 从句的后面执行的(即对 WHERE 筛选过的行分组),那我们还想对分组后的行在筛选一遍该如何是好捏?
Luckily, SQL allows us to do this by adding an additional _HAVING clause which is used specifically with the GROUP BY clause to allow us to filter grouped rows from the result set.
所幸 SQL 提供了 HAVING,它可以对 GROUP BY 从句分组后的结果进行筛选。语法:
|
|
The HAVING clause constraints are written the same way as the WHERE clause constraints, and are applied to the grouped rows. With our examples, this might not seem like a particularly useful construct, but if you imagine data with millions of rows with different properties, being able to apply additional constraints is often necessary to quickly make sense of the data.
HAVING 从句的写法和 WHERE 一样,并作用于分组后的行。在我们的例子里这个可能看起来没什么大用,但是如果放到一个几百万行的有不同性质的数据中,能额外对数据再进行一些限制性操作往往就很有必要了。
If you aren’t using the GROUP BY clause, a simple WHERE clause will suffice.
在不使用 GROUP BY 的情况下,一个简单的 WHERE 就足够了。
For this exercise, you are going to dive deeper into Employee data at the film studio. Think about the different clauses you want to apply for each task.
练习题还是用前面的 Employee 数据:
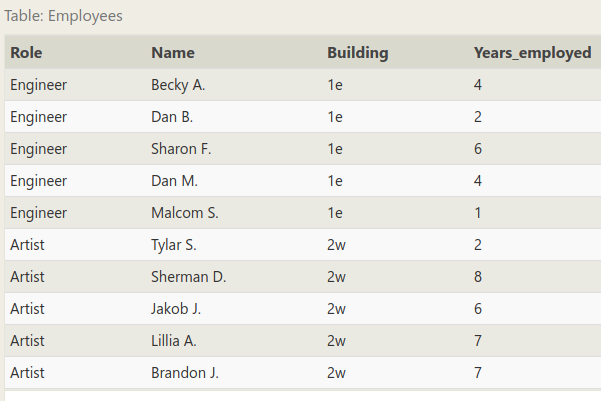
我们会再深入挖掘一下这个数据。做题的时候想一想你想用的那些从句。看题:
1. Find the number of Artists in the studio (without a HAVING clause)
不使用 HAVING 计算影楼里的 Artist 的数量,把 Artist 都选出来然后 COUNT 一下呗:
|
|
这就是上面那个说的,没有 GROUP BY 的时候,HAVING 可以靠 WHERE 实现。
我能说我没想到是怎么用 HAVING 的么 …. 上课没认真吗 … 思考了一下,首先肯定是 Role 分组。然后 HAVING 分组后只要 Artist,然后 COUNT:
|
|
2. Find the number of Employees of each role in the studio
每个工种雇员数量,那就是 Role 分组,雇员求和咯:
|
|
3. Find the total number of years employed by all Engineers
计算所有 Engineer 的工作时间。 首先 Role 分组跑不掉,只要 Engineer 的话 HAVING 跑不掉,然后时间求和咯:
|
|
K.O.
SQL Lesson 12: Order of execution of a Query
第 12 课,查询语句的执行顺序。
Now that we have an idea of all the parts of a query, we can now talk about how they all fit together in the context of a complete query. 现在我们基本了解了一个查询的各个部分,可以来聊一聊在一个完整的查询中这些部分是如何组合到一起的了。比如下面这个查询:
|
|
Each query begins with finding the data that we need in a database, and then filtering that data down into something that can be processed and understood as quickly as possible. Because each part of the query is executed sequentially, it’s important to understand the order of execution so that you know what results are accessible where. 每个查询都是以查找数据库中我们需要的数据开始,然后就是过滤直到得到能尽快处理和理解的东西为止。因为查询的各个部分是序贯执行的,因此理解执行顺序很重要,因为只有这样我们才能到哪里有什么结果。
Query order of execution
查询的执行顺序
1. FROM and JOINs
The FROM clause, and subsequent JOINs are first executed to determine the total working set of data that is being queried. This includes subqueries in this clause, and can cause temporary tables to be created under the hood containing all the columns and rows of the tables being joined. FROM 和 后续的 JOIN,包括其子查询,都是第一个执行的,以此来决定本次查询所要用到的全部数据。这可能会生成由参与合并的所有数据的行和列所组成的临时的表格。
2. WHERE
Once we have the total working set of data, the first-pass WHERE constraints are applied to the individual rows, and rows that do not satisfy the constraint are discarded. Each of the constraints can only access columns directly from the tables requested in the FROM clause. Aliases in the SELECT part of the query are not accessible in most databases since they may include expressions dependent on parts of the query that have not yet executed. 只要需要用的数据确定了,下面就是第一轮的 WHERE 逐行应用并去掉不满足条件的行。每个限制条件都只能访问到 FROM 语句里直接导入的所有的表格的列。此时通过 SELECT 生成的别名列在多数数据库里还无法访问,因为它们可能还依赖于查询语句中尚未被执行的部分。
3. GROUP BY
The remaining rows after the WHERE constraints are applied are then grouped based on common values in the column specified in the GROUP BY clause. As a result of the grouping, there will only be as many rows as there are unique values in that column. Implicitly, this means that you should only need to use this when you have aggregate functions in your query. WHERE 执行完后剩下的行会通过 GROUP BY 指定的列的值进行分组。分组后,分组后的数据会有多少行取决于分组使用的列有多少个唯一值。说白了,一般有聚合操作的时候才会用到分组。
4. HAVING
If the query has a GROUP BY clause, then the constraints in the HAVING clause are then applied to the grouped rows, discard the grouped rows that don’t satisfy the constraint. Like the WHERE clause, aliases are also not accessible from this step in most databases. 查询中有 GROUP BY 的时候,HAVING 后在分组后应用于分组后的行并去掉不满足条件的行。和 WHERE 类似,此时别名仍然不可用。
5. SELECT
Any expressions in the SELECT part of the query are finally computed. SELECT 会在最后执行。
(这也就是前面说由 SELECT 生成的别名一直不可用的原因)
6. DISTINCT
Of the remaining rows, rows with duplicate values in the column marked as DISTINCT will be discarded. 剩下的行中,DISTINCT 作用的列中的重复行会被去掉。
7. ORDER BY
If an order is specified by the ORDER BY clause, the rows are then sorted by the specified data in either ascending or descending order. Since all the expressions in the SELECT part of the query have been computed, you can reference aliases in this clause. 如果 ORDER BY 指定了排序,那么行会升序或降序排列。由于这个时候查询中的 SELECT 部分已经全部执行完了,我们可以引用别名了。(哇,终于可以了么)
8. LIMIT / OFFSET
Finally, the rows that fall outside the range specified by the LIMIT and OFFSET are discarded, leaving the final set of rows to be returned from the query. 最后的最后,LIMIT 和 OFFSET 指定范围之外的行会被去掉,最后剩下的就是返回的查询结果了。
Conclusion
结论 Not every query needs to have all the parts we listed above, but a part of why SQL is so flexible is that it allows developers and data analysts to quickly manipulate data without having to write additional code, all just by using the above clauses. 并不是所有的查询都会包含上面说到的这些部分,但是 SQL 就是这么的灵活,以至于仅仅靠上面提到的这些查询从句,开发者和数据分析师就可以在不需要写其他的代码的情况下迅速操纵数据。(这个牛吹得可以!)
练习时间又到了。
Here ends our lessons on SELECT queries, congrats of making it this far! This exercise will try and test your understanding of queries, so don’t be discouraged if you find them challenging. Just try your best. 最后通过 SELECT 查询结束我们的课程,恭喜你已经走了这么远了。本次练习将会考察我们对于查询的理解,觉得有点难的话不要灰心。尽力做!
你们这么一说我还有点小忐忑呢 ….
数据还是我们滚瓜烂熟的电影票房数据:
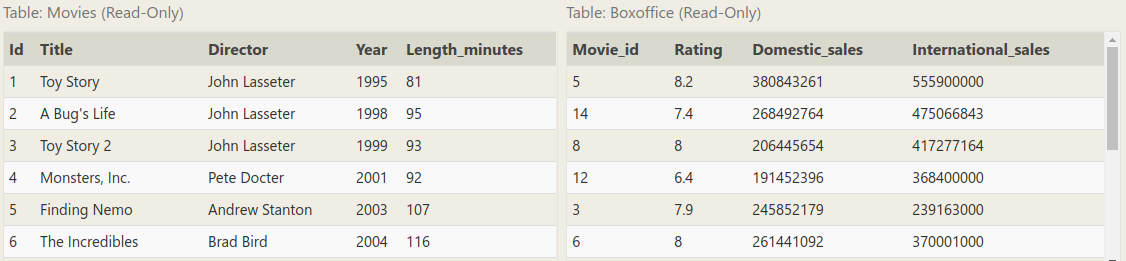
1. Find the number of movies each director has directed
查询每个导演的作品数。 嗯,导演分组,电影求和:
|
|
开始一直把 COUNT 写成 SUM 导致卡了好久 23333333。想想其实不是电影求和,而是计数。
2. Find the total domestic and international sales that can be attributed to each director
每个导演的总国内外票房。 导演分组,票房分别求和:
|
|
好吧,英语理解的问题,我开始以为是国内外分别求和,又瞎浪费了一小会儿。
2018-07-27 更新
PostgreSQL 文档
PostgreSQL 文档 Chapter 2. The SQL Langua - 2.7. Aggregate Functions :
It is important to understand the interaction between aggregates and SQL’s WHERE and HAVING clauses. The fundamental difference between WHERE and HAVING is this: WHERE selects input rows before groups and aggregates are computed (thus, it controls which rows go into the aggregate computation), whereas HAVING selects group rows after groups and aggregates are computed. Thus, the WHERE clause must not contain aggregate functions; it makes no sense to try to use an aggregate to determine which rows will be inputs to the aggregates. On the other hand, the HAVING clause always contains aggregate functions. (Strictly speaking, you are allowed to write a HAVING clause that doesn’t use aggregates, but it’s seldom useful. The same condition could be used more efficiently at the WHERE stage.)
理解聚集和 SQL 的 WHERE 以及 HAVING 子句之间的关系十分重要。WHERE 和 HAVING 的之间有着本质的区别:WHERE 在分组和聚合计算之前选取输入行(即 WHERE 将控制哪些行进入聚合计算), 而 HAVING 则是对分组和聚合之后的已分组的行进行选择操作。因此,WHERE 子句不能包含聚合函数; 因为通过一个聚合运算来选择另一个聚合运算的输入是行不通的。相反,HAVING 子句则总会包含聚合函数(严格地说,使用没有聚合运算的 HAVING 子句的是可以的, 但这样做多半没什么用。这种时候其实直接用 WHERE 就行了)。
结合 SQL Lesson 12: Order of execution of a Query 这一节来看就能很好的理解了。
文章作者 Jackie
上次更新 2019-01-06 (b1fedc7)